Framework
Build & Benchmark: How to Validate an MVP Before You Scale
Most teams do not fail because they cannot build software. They fail because they build too much before they know what reality thinks.
A prototype can make an idea visible. A production build can make it scalable. But between those two sits a dangerous gap: does the product create enough user signal to deserve more investment?
That is the job of Build & Benchmark.
Build & Benchmark is Synetica’s focused MVP phase. We take a validated blueprint, build the smallest real product that can test the riskiest assumptions, put it in front of real users, and measure whether the signal is strong enough to continue.
No theatre. No demo-day optimism. No “the market will love this once we add five more features.” Just a working product, real behaviour, and a decision.
Table of Contents
- What Build & Benchmark Actually Means
- Why Building Alone Is Not Enough
- The Build & Benchmark Method
- What to Benchmark
- How to Read the Results
- Common Mistakes
- FAQ
What Build & Benchmark Actually Means
Build & Benchmark has two equal halves.
Build means creating a real MVP that users can touch. Not a slide deck. Not a Figma walkthrough. Not a beautiful prototype held together by hope. It should have enough product quality to test the intended workflow, capture data, and show whether users can complete the core action.
Benchmark means measuring the MVP against explicit success criteria. Before we build, we define what would count as useful signal: activation rate, task completion, willingness to pay, acquisition cost, retention, or operational efficiency. Then we test.
The point is not to prove that the idea is brilliant. The point is to find out what the evidence says while the cost of changing direction is still low.
Why Building Alone Is Not Enough
Modern development tools make it easier to ship interfaces quickly. That is useful. It is also dangerous.
When teams can build faster, they often skip the discipline that makes building worth it: deciding what needs to be true for the product to work.
CB Insights has repeatedly shown that lack of market need is one of the biggest reasons startups fail. The language changes by report, but the pattern is familiar: teams build something technically functional that the market does not urgently need. Nielsen Norman Group also notes that small usability tests can reveal many interface issues early, but usability is only one layer. A product can be easy to use and still not matter enough.
That is why Build & Benchmark measures both usability and business signal.
A good MVP test should answer four questions:
- Can users complete the core workflow? If not, the product is too hard to use.
- Do users care enough to come back or ask for access? If not, the problem may not be painful.
- Can we acquire users through realistic channels? If not, go-to-market may be the actual risk.
- Does the economics make sense? If acquisition, delivery, or support cost is too high, scale will hurt.
The build is the instrument. The benchmark is the reading.
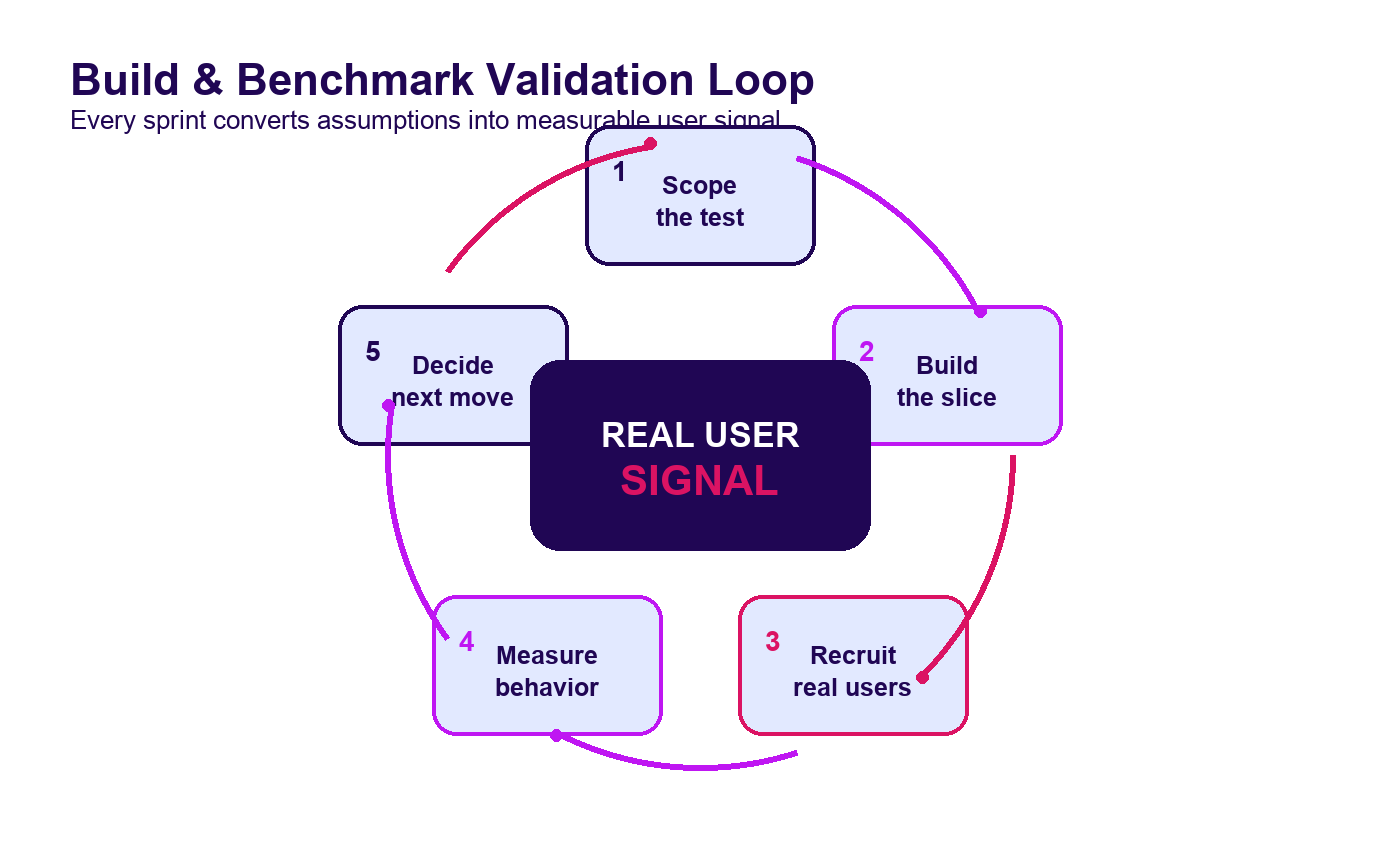
The Build & Benchmark Method
Build & Benchmark works best after a Blueprint phase because the hardest decisions are already mapped: target user, problem, workflow, feature priority, technical architecture, and assumptions. Without that clarity, the MVP becomes a negotiation with everyone’s favourite feature list. Cute, but expensive.
Here is the operating model:
| Phase | What happens | Key output | Decision question |
|---|---|---|---|
| 1. Scope the test | Define the riskiest assumption and the smallest usable product | MVP test brief | What must we learn? |
| 2. Build the slice | Build the core workflow with production-minded foundations | Working MVP | Can users complete the job? |
| 3. Recruit real users | Use realistic acquisition channels, not internal cheerleaders | User cohort | Can we reach the market? |
| 4. Measure behaviour | Track activation, task completion, feedback, drop-off, and cost | Benchmark dashboard | Is the signal strong enough? |
| 5. Decide | Recommend go, iterate, pivot, or stop | Go/no-go report | What should we do next? |
This approach keeps the team honest. Every feature must explain which assumption it helps test. If it does not improve learning, it waits.

What to Benchmark
A benchmark is only useful if it matches the product risk.
For a B2B workflow product, adoption and task completion may matter more than click-through rate. For a consumer app, activation and repeat usage may be the early signal. For an internal operations tool, the benchmark may be time saved, error reduction, or handoff quality.
We usually group benchmarks into four categories:
1. User Value Signal
This measures whether the product solves a real problem.
Useful indicators:
- percentage of users who complete the core action
- number of users who ask to continue using it
- qualitative pain level before and after the workflow
- drop-off points in the journey
A founder saying “users loved it” is not enough. Users are polite. Behaviour is less polite, which makes it more useful.
2. Usability Signal
This measures whether users can use the product without heroic support.
Useful indicators:
- task completion rate
- time to complete the core workflow
- number of support prompts needed
- error rate by step
If users need a 20-minute explanation before using the MVP, you have not validated the product. You have validated your ability to do live customer support.
3. Acquisition Signal
This measures whether the market can be reached through real channels.
Useful indicators:
- landing page conversion
- cost per qualified lead or user
- channel response quality
- number of users recruited within the test window
This matters because many products look good in founder networks and collapse in the open market. Friends are a terrible benchmark. They want you to feel okay.
4. Economic Signal
This measures whether the product has a plausible path to scale.
Useful indicators:
- cost to acquire a user
- cost to serve a user
- expected pricing or willingness to pay
- operational effort per transaction
A product can be desirable and still structurally unprofitable. Benchmarking catches that before the team adds headcount, infrastructure, and emotional attachment.

How to Read the Results
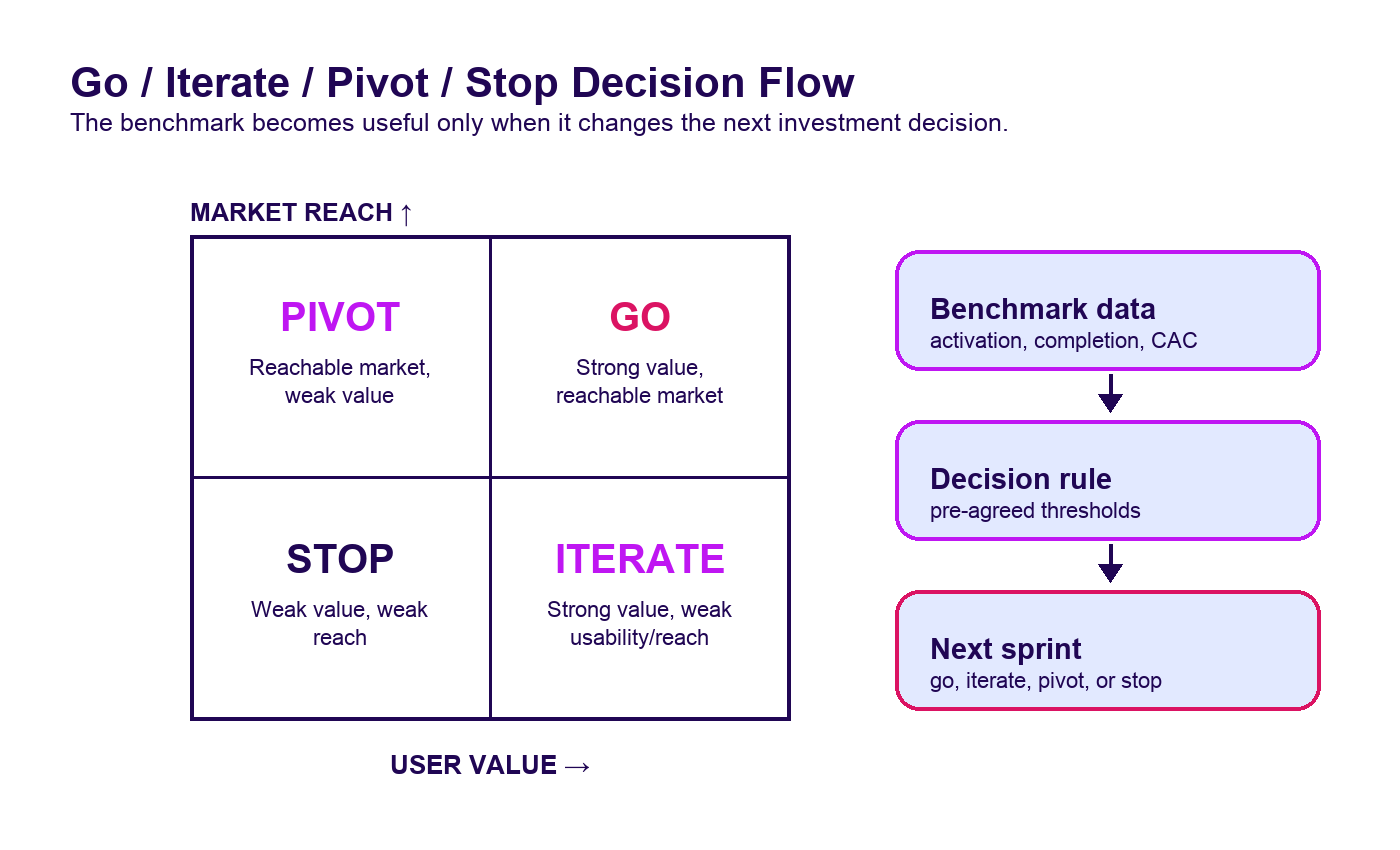
The output of Build & Benchmark is not a mood board of feedback. It is a decision report.
We usually classify results into four paths:
| Result pattern | What it means | Recommended action |
|---|---|---|
| Strong user value + acceptable acquisition | The product deserves more investment | Go: harden the product and prepare launch |
| Strong user value + weak usability | The problem is real, but the workflow needs work | Iterate: simplify the product before scaling |
| Weak user value + strong acquisition | The market is reachable, but the offer is wrong | Pivot: adjust problem, promise, or audience |
| Weak user value + weak acquisition | The current direction is not justified | Stop or return to discovery |
The best outcome is not always “go.” Sometimes the best outcome is discovering that the idea should not consume the next six months. That is not failure. That is capital discipline.
Common Mistakes
Mistake 1: Building a mini enterprise system
An MVP is not a smaller version of the final product. It is a learning tool. If the test is about whether customers will upload invoices, you do not need advanced role management, twelve dashboard views, and an admin theme selector. Nobody needs the theme selector. The theme selector can sit quietly and think about what it has done.
Mistake 2: Testing with the wrong users
Internal teams, friends, and warm introductions are useful for early feedback. They are not enough for market validation. Build & Benchmark should include people who behave like the real target customer and arrive through channels you may use later.
Mistake 3: Measuring vanity metrics
Page views, likes, and generic signups can be misleading. Measure the behaviour closest to value: completed workflow, repeat usage, purchase intent, qualified lead quality, or operational time saved.
Mistake 4: Changing benchmarks after the result arrives
This is where teams get slippery. If the benchmark was 30 users with 60% activation, do not move the goalpost after getting 22 users and 18% activation. The data may still be useful, but it is not the same decision.
Mistake 5: Treating AI speed as validation
AI-assisted development can reduce build time. It does not reduce the need for user signal. Faster shipping only helps if the thing shipped is pointed at the right question.
When Build & Benchmark Is the Right Move
Use Build & Benchmark when:
- you already know the target user and problem
- you have a clear hypothesis to test
- the next investment decision is meaningful
- you need evidence before committing to a full production build
- leadership needs more than opinions to approve the next phase
Do not use it when the idea is still vague. If the problem, user, and workflow are unclear, start with Blueprint first. Otherwise you will build a very precise solution to a blurry question.
The Synetica View
Build & Benchmark is our way of keeping product development honest.
We like building. Building creates momentum. But momentum without measurement is just a faster way to hit the wall.
The right sequence is simple:
- Clarify the problem.
- Build the smallest real product that can test it.
- Benchmark the result with real users.
- Decide what deserves the next investment.
That is how teams move from idea to traction without turning every assumption into a six-month invoice.
FAQ
How long does Build & Benchmark take?
A focused cycle usually takes 4–6 weeks, depending on scope, integrations, and user recruitment. The goal is not to build everything. The goal is to build enough to test the most important assumption.
How many users do we need for a benchmark?
It depends on the product risk. For usability issues, a small test can reveal a lot. For market signal, we prefer a larger cohort with realistic acquisition. Synetica often uses 30 real users as a practical early benchmark: big enough to reveal patterns, small enough to move fast.
Is Build & Benchmark the same as MVP development?
Not exactly. MVP development focuses on building the first version. Build & Benchmark includes the build, but adds structured measurement and a go/no-go decision. The benchmark is what prevents the MVP from becoming just another unfinished product.
What happens if the benchmark fails?
Then you have learned something valuable before spending more. The decision may be to iterate, pivot, or stop. A failed benchmark is cheaper than a failed scale-up.
Can existing products use Build & Benchmark?
Yes. It is useful for new features, product pivots, internal tools, and market expansion. The method is the same: define the risky assumption, build the smallest test, measure real behaviour, then decide.
References
Need help putting this into practice?
Book a Blueprint session and we'll turn the ideas in this article into your next validated release.
Book a Discovery Call